签名(signature) 1 2 public class HashMap <K ,V > extends AbstractMap <K ,V > implements Map <K ,V >, Cloneable , Serializable
可以看到HashMap继承了
标记接口Cloneable ,用于表明HashMap对象会重写java.lang.Object#clone()方法,HashMap实现的是浅拷贝(shallow copy)。
标记接口Serializable ,用于表明HashMap对象可以被序列化
比较有意思的是,HashMap同时继承了抽象类AbstractMap与接口Map,因为抽象类AbstractMap的签名为
1 public abstract class AbstractMap <K ,V > implements Map <K ,V >
Stack Overflow 上解释到:
在语法层面继承接口Map是多余的,这么做仅仅是为了让阅读代码的人明确知道HashMap是属于Map体系的,起到了文档的作用
AbstractMap相当于个辅助类,Map的一些操作这里面已经提供了默认实现,后面具体的子类如果没有特殊行为,可直接使用AbstractMap提供的实现。
1 It's evil, don't use it.
Cloneable这个接口设计的非常不好,最致命的一点是它里面竟然没有clone方法,也就是说我们自己写的类完全可以实现这个接口的同时不重写clone方法。但是clone方法是Object里面有的,如果一个对象没有实现Cloneable接口而使用clone方法会抛出CloneNotSupportedException 异常。
关于Cloneable的不足,大家可以去看看《Effective Java》一书的作者给出的理由 ,在所给链接的文章里,Josh Bloch也会讲如何实现深拷贝比较好,我这里就不在赘述了。
JDK 1.7
JDK 1.8
Map虽然并不是Collection,但是它提供了三种“集合视角”(collection views),与下面三个方法一一对应:
Set keySet(),提供key的集合视角Collection values(),提供value的集合视角Set entrySet(),提供key-value序对的集合视角,这里用内部类Map.Entry表示序对
AbstractMap对Map中的方法提供了一个基本实现,减少了实现Map接口的工作量。
如果要实现个不可变(unmodifiable)的map,那么只需继承AbstractMap,然后实现其entrySet方法,这个方法返回的set不支持add与remove,同时这个set的迭代器(iterator)不支持remove操作即可。
相反,如果要实现个可变(modifiable)的map,首先继承AbstractMap,然后重写(override)AbstractMap的put方法,同时实现entrySet所返回set的迭代器的remove方法即可。
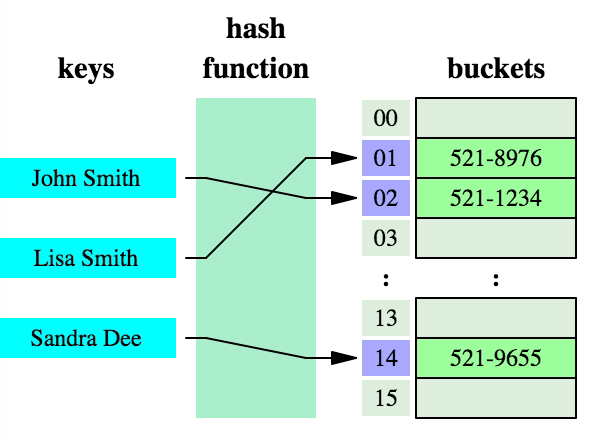
设计理念(design concept) 哈希表(hash table) HashMap是一种基于哈希表(hash table) 实现的map,哈希表(也叫关联数组)一种通用的数据结构,大多数的现代语言都原生支持,其概念也比较简单:key经过hash函数作用后得到一个槽(buckets或slots)的索引(index),槽中保存着我们想要获取的值,如下图所示
很容易想到,一些不同的key经过同一hash函数后可能产生相同的索引,也就是产生了冲突,这是在所难免的。
所以利用哈希表这种数据结构实现具体类时,需要:
设计个好的hash函数,使冲突尽可能的减少
其次是需要解决发生冲突后如何处理。
后面会重点介绍HashMap是如何解决这两个问题的。
HashMap的一些特点
线程非安全,并且允许key与value都为null值,HashTable与之相反,为线程安全,key与value都不允许null值 ,会抛出NullPointerException。不保证其内部元素的顺序,而且随着时间的推移,同一元素的位置也可能改变(resize的情况)
put、get操作的时间复杂度为O(1)。
遍历其集合视角的时间复杂度与其容量(capacity,槽的个数)和现有元素的大小(entry的个数)成正比,所以如果遍历的性能要求很高,不要把capactiy设置的过高或把平衡因子(load factor,当entry数大于capacity*loadFactor时,会进行resize,reside会导致key进行rehash)设置的过低。
由于HashMap是线程非安全的,这也就是意味着如果多个线程同时对一hashmap的集合试图做迭代时有结构的上改变(添加、删除entry,只改变entry的value的值不算结构改变),那么会报ConcurrentModificationException ,专业术语叫fail-fast,尽早报错对于多线程程序来说是很有必要的。
Map m = Collections.synchronizedMap(new HashMap(...)); 通过这种方式可以得到一个线程安全的map。
源码分析(JDK 1.7) 主要属性 1 2 3 4 5 6 7 transient int size;static final int DEFAULT_INITIAL_CAPACITY = 1 << 4 ; static final int MAXIMUM_CAPACITY = 1 << 30 ;static final float DEFAULT_LOAD_FACTOR = 0.75f ;transient Entry<K,V> table= (Entry<K,V>[]) EMPTY_TABLE; int threshold;
当bucket中的entries的数目大于capacity*load factor时就需要调整bucket的大小为当前的2倍。
若加载因子设置过大,则填满的元素越多,无疑空间利用率变高了,但是冲突的机会增加了,冲突的越多,链表就会变得越长,那么查找效率就会变得更低;
若加载因子设置过小,则填满的元素越少,那么空间利用率变低了,表中数据将变得更加稀疏,但是冲突的机会减小了,这样链表就不会太长,查找效率变得更高。
负载因子一般为默认的 0.75
put方法实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public V put (K key, V value) if (table == EMPTY_TABLE) { inflateTable(threshold); } if (key == null ) return putForNullKey(value); int hash = hash(key); int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null ; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this ); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null ; }
inflateTable 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 private void inflateTable (int toSize) int capacity = roundUpToPowerOf2(toSize); threshold = (int ) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1 ); table = new Entry[capacity]; initHashSeedAsNeeded(capacity); } private static int roundUpToPowerOf2 (int number) int rounded = number >= MAXIMUM_CAPACITY ? MAXIMUM_CAPACITY : (rounded = Integer.highestOneBit(number)) != 0 ? (Integer.bitCount(number) > 1 ) ? rounded << 1 : rounded : 1 ; return rounded; }
在inflateTable方法内,首先初始化数组容量大小,数组容量永远是2的幂(下面会分析为什么要这样)。所以调用roundUpToPowerOf2方法将传进来的容量转换成最接近2的次幂的值,然后重新计算阈值threadshold = 容量 x 加载因子,最后初始化table。所以刚开始初始化table不是在HashMap的构造函数里,因为构造函数中仅仅简单的将传进去的容量作为阈值。
真正初始化table是在第一次往HashMap中put数据的时候。
初始化好了table后,就开始往table中存入数据了,table中存的是Entry实体,而put方法传进来的是key和value,所以接下来要做两件事:
找到table数组中要存入的位置;
将key和value封装到Entry中存入。
我们再回到put方法中,先来分析第一步,找存储的位置就要依靠key的值了,因为需要用key的值来计算hash值,根据hash值来决定在table中的位置。首先当key为null时,调用putForNullKey方法,该方法内部实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 private V putForNullKey (V value) for (Entry<K,V> e = table[0 ]; e != null ; e = e.next) { if (e.key == null ) { V oldValue = e.value; e.value = value; e.recordAccess(this ); return oldValue; } } modCount++; addEntry(0 , null , value, 0 ); return null ; }
hash方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 final int hash (Object k) int h = hashSeed; if (0 != h && k instanceof String) { return sun.misc.Hashing.stringHash32((String) k); } h ^= k.hashCode(); h ^= (h >>> 20 ) ^ (h >>> 12 ); return h ^ (h >>> 7 ) ^ (h >>> 4 ); }
1 2 3 4 5 static int indexFor (int h, int length) return h & (length-1 ); }
首先,h & (length-1)相当于h & length,但是h % length效率比较低(HashTable中是这儿干的)。为啥h & (length-1)相当于h % length呢?现在假设length为2的幂,那么length就可以表示成100……00的形式(表示至少1个0),那么length-1就是01111….11。对于任意小于length的数h来说,与01111…11做&后都是h本身,对于h=length来说,&后结果为0,对于大于length的数h,&过后相当于h-j*length,也就是h % length。这也就是为啥容量必须为2的幂了,为了优化,好做&运算,效率高。
其次,length为2的次幂的话,是偶数,这样length-1为奇数,奇数的最后一位是1,这样便保证了h & (length-1)的最后一位可能为0也可能为1(取决于h的值),即结果可能为奇数,也可能为偶数,这样便可以保证散列的均匀性,即均匀分布在数组table中;而如果length为奇数的话,很明显length-1为偶数,它的最后一位是0,这样h & (length-1)的最后一位肯定为0,级只能为偶数,这样任何hash值都会被映射到数组的偶数下标位置上,这便浪费了近一半的空间!因此,length去2的整数次幂,也是为了使不同hash值发生碰撞的概率较小,这样就能使元素在哈希表中均匀的散列。
addEntry方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void addEntry (int hash, K key, V value, int bucketIndex) if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length); hash = (null != key) ? hash(key) : 0 ; bucketIndex = indexFor(hash, table.length); } createEntry(hash, key, value, bucketIndex); } void createEntry (int hash, K key, V value, int bucketIndex) Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<>(hash, key, value, e); size++; }
resize扩容方法 1 2 3 4 5 6 7 8 9 10 11 12 13 void resize (int newCapacity) Entry[] oldTable = table; int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return ; } Entry[] newTable = new Entry[newCapacity]; transfer(newTable, initHashSeedAsNeeded(newCapacity)); table = newTable; threshold = (int )Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1 ); }
我们在扩充HashMap的时候,不需要重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”。可以看看下图为16扩充为32的resize示意图:
扩充HashMap的时候,不需要重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”。可以看看下图为16扩充为32的resize示意图:
get方法实现 1 2 3 4 5 6 7 public V get (Object key) if (key == null ) return getForNullKey(); Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue(); }
HashMap是允许key为null的,单独一个方法来处理,key为null的元素在0号桶
1 2 3 4 5 6 7 8 9 10 private V getForNullKey () if (size == 0 ) { return null ; } for (Entry<K,V> e = table[0 ]; e != null ; e = e.next) { if (e.key == null ) return e.value; } return null ; }
getEntry
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 final Entry<K,V> getEntry (Object key) if (size == 0 ) { return null ; } int hash = (key == null ) ? 0 : hash(key); for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null ; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null ; }
1 2 3 4 5 6 7 8 9 10 11 12 public int size () return size; } public boolean isEmpty () return size == 0 ; } public boolean containsKey (Object key) return getEntry(key) != null ; }
源码分析(JDK 1.8) 1.7和1.8的区别 在JDK1.7中,HashMap采用哈希表+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,HashMap采用哈希表+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
数据结构 1 涉及到的数据结构:处理hash冲突的链表和红黑树以及哈希表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 static class Node <K ,V > implements Map .Entry <K ,V > final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this .hash = hash; this .key = key; this .value = value; this .next = next; } public final K getKey () return key; } public final V getValue () return value; } public final String toString () return key + "=" + value; } public final int hashCode () return Objects.hashCode(key) ^ Objects.hashCode(value); } public final V setValue (V newValue) V oldValue = value; value = newValue; return oldValue; } public final boolean equals (Object o) if (o == this ) return true ; if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>)o; if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) return true ; } return false ; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 static final class TreeNode <K ,V > extends LinkedHashMap .Entry <K ,V > TreeNode<K,V> parent; TreeNode<K,V> left; TreeNode<K,V> right; TreeNode<K,V> prev; boolean red; TreeNode(int hash, K key, V val, Node<K,V> next) { super (hash, key, val, next); } final TreeNode<K,V> root () for (TreeNode<K,V> r = this , p;;) { if ((p = r.parent) == null ) return r; r = p; } } ......
1 transient Node<K,V>[] table;
首先有一个每个元素都是链表(可能表述不准确)的数组,当添加一个元素(key-value)时,就首先计算元素key的hash值,以此确定插入数组中的位置,但是可能存在同一hash值的元素已经被放在数组同一位置了,这时就添加到同一hash值的元素的后面,他们在数组的同一位置,但是形成了链表,所以说数组存放的是链表。而当链表长度太长时,链表就转换为红黑树,这样大大提高了查找的效率。
主要属性 1 2 3 4 5 6 7 8 9 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4 ; static final int MAXIMUM_CAPACITY = 1 << 30 ;static final float DEFAULT_LOAD_FACTOR = 0.75f ; static final int TREEIFY_THRESHOLD = 8 ;static final int UNTREEIFY_THRESHOLD = 6 ;static final int MIN_TREEIFY_CAPACITY = 64 ;transient int size;transient int modCount; int threshold;
resize扩容 当put时,如果发现目前的bucket占用程度已经超过了Load Factor所希望的比例,那么就会发生resize。在resize的过程,简单的说就是把bucket扩充为2倍,之后重新计算index,把节点再放到新的bucket中。resize的注释是这样描述的:
Initializes or doubles table size. If null, allocates in accord with initial capacity target held in field threshold. Otherwise, because we are using power-of-two expansion, the elements from each bin must either stay at same index , or move with a power of two offset in the new table.
大致意思就是说,当超过限制的时候会resize,然而又因为我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。
怎么理解呢?例如我们从16扩展为32时,具体的变化如下所示:
因此元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
因此,我们在扩充HashMap的时候,不需要重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”。可以看看下图为16扩充为32的resize示意图:
这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null ) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0 ; if (oldCap > 0 ) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1 ) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1 ; } else if (oldThr > 0 ) newCap = oldThr; else { newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int )(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0 ) { float ft = (float )newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float )MAXIMUM_CAPACITY ? (int )ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings ({"rawtypes" ,"unchecked" }) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; if (oldTab != null ) { for (int j = 0 ; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null ) { oldTab[j] = null ; if (e.next == null ) newTab[e.hash & (newCap - 1 )] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this , newTab, j, oldCap); else { Node<K,V> loHead = null , loTail = null ; Node<K,V> hiHead = null , hiTail = null ; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0 ) { if (loTail == null ) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null ) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null ); if (loTail != null ) { loTail.next = null ; newTab[j] = loHead; } if (hiTail != null ) { hiTail.next = null ; newTab[j + oldCap] = hiHead; } } } } } return newTab; }
hash方法 1 2 3 4 static final int hash (Object key) int h; return (key == null ) ? 0 : (h = key.hashCode()) ^ (h >>> 16 ); }
首先由key值通过hashcode()获取hash值h,再通过h^ (h >>> 16)得到所在数组位置。一般对于哈希表的散列常用的方法有直接定址法,除留余数法等,既要便于计算,又能减少冲突。
get方法 1 2 3 4 public V get (Object key) Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 final Node<K,V> getNode (int hash, Object key) Node<K,V>[] tab; Node<K,V> first, e; int n; K k; if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1 ) & hash]) != null ) { if (first.hash == hash && ((k = first.key) == key || (key != null && key.equals(k)))) return first; if ((e = first.next) != null ) { if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null ); } } return null ; }
get函数大致的思路为:
bucket里的第一个节点,直接命中;
如果有冲突,则通过key.equals(k)去查找对应的entry
在Java 8之前的实现中是用链表解决冲突的,在产生碰撞的情况下,进行get时,两步的时间复杂度是O(1)+O(n)。因此,当碰撞很厉害的时候n很大,O(n)的速度显然是影响速度的。
因此在Java 8中,利用红黑树替换链表,这样复杂度就变成了O(1)+O(logn)了。
put方法 1 2 3 public V put (K key, V value) return putVal(hash(key), key, value, false , true ); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 final V putVal (int hash, K key, V value, boolean onlyIfAbsent, boolean evict) Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0 ) n = (tab = resize()).length; if ((p = tab[i = (n - 1 ) & hash]) == null ) tab[i] = newNode(hash, key, value, null ); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this , tab, hash, key, value); else { for (int binCount = 0 ; ; ++binCount) { if ((e = p.next) == null ) { p.next = newNode(hash, key, value, null ); if (binCount >= TREEIFY_THRESHOLD - 1 ) treeifyBin(tab, hash); break ; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break ; p = e; } } if (e != null ) { V oldValue = e.value; if (!onlyIfAbsent || oldValue == null ) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null ; }
put函数大致的思路为:
对key做hash,然后再计算index;
如果没碰撞直接放到bucket里;
如果碰撞了,以链表的形式存在buckets后;
如果碰撞导致链表过长(大于等于TREEIFY_THRESHOLD),就把链表转换成红黑树;
如果节点已经存在就替换old value(保证key的唯一性)
如果bucket满了(超过load factor*current capacity),就要resize。
参考:
GC: HashMap - java.util.HashMap (.java) - 1.7 7u40-b43 GC: HashMap - java.util.HashMap (.java) - 1.8 8u40-b25 Java HashMap 源码解析 Java类集框架之HashMap(JDK1.8)源码剖析 Java HashMap工作原理及实现 java集合框架08——HashMap和源码分析